





Cobertura是一种开源的代码覆盖率工具,用于衡量软件测试中代码的覆盖程度。它能够分析和报告测试套件对源代码的覆盖情况,帮助开发人员确定哪些部分的代码已经被测试覆盖,哪些部分还未经过充分的测试。
Cobertura工具使用Java字节码分析技术,能够跟踪代码执行过程中每个分支、条件和方法调用的覆盖情况。它通过在代码中插入特定的计数器和跟踪器来收集覆盖率信息,然后生成详细的报告,显示每个类、方法和代码行的覆盖率统计数据。
在测试过程中,Cobertura可以与各种测试框架(如JUnit、TestNG等)和构建工具(如Ant、Maven等)集成使用。它可以在编译期或运行期执行测试,并收集覆盖率数据。生成的报告通常以HTML格式呈现,提供了直观、易于理解的覆盖率统计和可视化展示。
通过使用cobertura覆盖率测试工具,开发人员可以评估测试套件的质量和完整性,找出代码中未被覆盖的部分,进而改进测试策略、增强测试用例的覆盖范围,提高软件质量和稳定性。此外,Cobertura还支持与持续集成工具集成,提供覆盖率报告的历史记录和趋势分析,帮助团队进行质量控制和性能优化。
这些是代码覆盖率可以试图回答的问题。总之,出于以下原因我们需要测量代码覆盖率:
● 了解我们的测试用例对源代码的测试效果
● 了解我们是否进行了足够的测试
● 在软件的整个生命周期内保持测试质量
注:代码覆盖率不是灵丹妙药,覆盖率测量不能替代良好的代码审查和优秀的编程实践。
通常,我们应该采用合理的覆盖目标,力求在代码覆盖率在所有模块中实现均匀覆盖,而不是只看最终数字的是否高到令人满意。
举例:假设代码覆盖率只在某一些模块代码覆盖率很高,但在一些关键模块并没有足够的测试用例覆盖,那样虽然代码覆盖率很高,但并不能说明产品质量就很高。
利用 Cobertura 报告,可以找出代码中未测试的部分并针对它们编写测试。例如,图 3 显示 Jaxen 需要进行一些测试,运用 name() 函数对文字节点、注释节点、处理指令节点、属性节点和名称空间节点进行测试。
(几乎)不留下任何未测试的代码
是否有一些可以测试但不应测试的内容?这取决于您问的是谁。在 JUnit FAQ 中,J. B. RAInsberger 写到“一般的看法是:如果 自身 不会出问题,那么它会因为太简单而不会出问题。第一个例子是 getX() 方法。假定 getX() 方法只提供某一实例变量的值。在这种情况下,除非编译器或者解释器出了问题,否则 getX() 是不会出问题的。因此,不用测试 getX(),测试它不会带来任何好处。对于 setX() 方法来说也是如此,不过,如果 setX() 方法确实要进行任何参数验证,或者说确实有副作用,那么还是有必要对其进行测试。”
阅读 Cobertura 输出
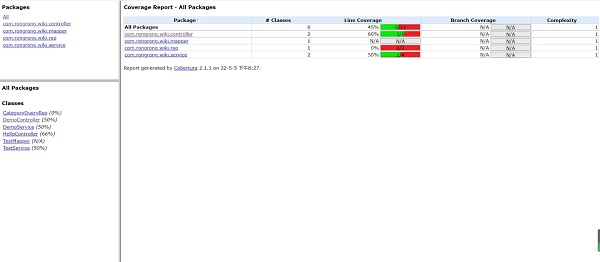
我们首先查看生成的 Cobertura 输出。图 1 显示了对 Jaxen 测试包运行 Cobertura 生成的报告。从该报告中,可以看到从很好(在 org.jaxen.expr.iter 包中几乎是 100%)到极差(在 org.jaxen.dom.html 中完全没有覆盖)的覆盖率结果。
Cobertura 通过被测试的行数和被测试的分支数来计算覆盖率。第一次测试时,两种测试方法之间的差别并不是很重要。Cobertura 还为类计算平均 McCabe 复杂度。
可以深入挖掘 HTML 报告,了解特定包或者类的覆盖率。图 2 显示了 org.jaxen.function 包的覆盖率统计。在这个包中,覆盖率的范围从 SumFunction 类的 100% 到 IdFunction 类的仅为 5%。
进一步深入到单独的类中,具体查看哪一行代码没有测试到。图 3 显示了 NameFunction 类中的部分覆盖率。最左边一栏显示行号。后一栏显示了执行测试时这一行被执行的次数。可以看出,第 112 行被执行了 100 次,第 114 行被执行了 28 次。用红色突出显示的那些行则根本没有测试到。这个报告表明,虽然从总体上说该方法被测试到了,但实际上还有许多分支没有测试到。
什么是代码覆盖率?
代码覆盖率是对整个测试过程中被执行的代码的衡量,它能测量源代码中的哪些语句在测试中被执行,哪些语句尚未被执行。为什么要测量代码覆盖率?
众所周知,测试可以提高软件版本的质量和可预测性。但是,你知道你的单元测试甚至是你的功能测试实际测试代码的效果如何吗?是否还需要更多的测试?这些是代码覆盖率可以试图回答的问题。总之,出于以下原因我们需要测量代码覆盖率:
● 了解我们的测试用例对源代码的测试效果
● 了解我们是否进行了足够的测试
● 在软件的整个生命周期内保持测试质量
注:代码覆盖率不是灵丹妙药,覆盖率测量不能替代良好的代码审查和优秀的编程实践。
通常,我们应该采用合理的覆盖目标,力求在代码覆盖率在所有模块中实现均匀覆盖,而不是只看最终数字的是否高到令人满意。
举例:假设代码覆盖率只在某一些模块代码覆盖率很高,但在一些关键模块并没有足够的测试用例覆盖,那样虽然代码覆盖率很高,但并不能说明产品质量就很高。
cobertura覆盖率测试工具功能
确认遗漏的测试利用 Cobertura 报告,可以找出代码中未测试的部分并针对它们编写测试。例如,图 3 显示 Jaxen 需要进行一些测试,运用 name() 函数对文字节点、注释节点、处理指令节点、属性节点和名称空间节点进行测试。
(几乎)不留下任何未测试的代码
是否有一些可以测试但不应测试的内容?这取决于您问的是谁。在 JUnit FAQ 中,J. B. RAInsberger 写到“一般的看法是:如果 自身 不会出问题,那么它会因为太简单而不会出问题。第一个例子是 getX() 方法。假定 getX() 方法只提供某一实例变量的值。在这种情况下,除非编译器或者解释器出了问题,否则 getX() 是不会出问题的。因此,不用测试 getX(),测试它不会带来任何好处。对于 setX() 方法来说也是如此,不过,如果 setX() 方法确实要进行任何参数验证,或者说确实有副作用,那么还是有必要对其进行测试。”
阅读 Cobertura 输出
我们首先查看生成的 Cobertura 输出。图 1 显示了对 Jaxen 测试包运行 Cobertura 生成的报告。从该报告中,可以看到从很好(在 org.jaxen.expr.iter 包中几乎是 100%)到极差(在 org.jaxen.dom.html 中完全没有覆盖)的覆盖率结果。
Cobertura 通过被测试的行数和被测试的分支数来计算覆盖率。第一次测试时,两种测试方法之间的差别并不是很重要。Cobertura 还为类计算平均 McCabe 复杂度。
可以深入挖掘 HTML 报告,了解特定包或者类的覆盖率。图 2 显示了 org.jaxen.function 包的覆盖率统计。在这个包中,覆盖率的范围从 SumFunction 类的 100% 到 IdFunction 类的仅为 5%。
进一步深入到单独的类中,具体查看哪一行代码没有测试到。图 3 显示了 NameFunction 类中的部分覆盖率。最左边一栏显示行号。后一栏显示了执行测试时这一行被执行的次数。可以看出,第 112 行被执行了 100 次,第 114 行被执行了 28 次。用红色突出显示的那些行则根本没有测试到。这个报告表明,虽然从总体上说该方法被测试到了,但实际上还有许多分支没有测试到。

































